Logging at the edge
I was thinking about how logging plays a huge role in many ingest pipelines. Usually I see architectures like this:
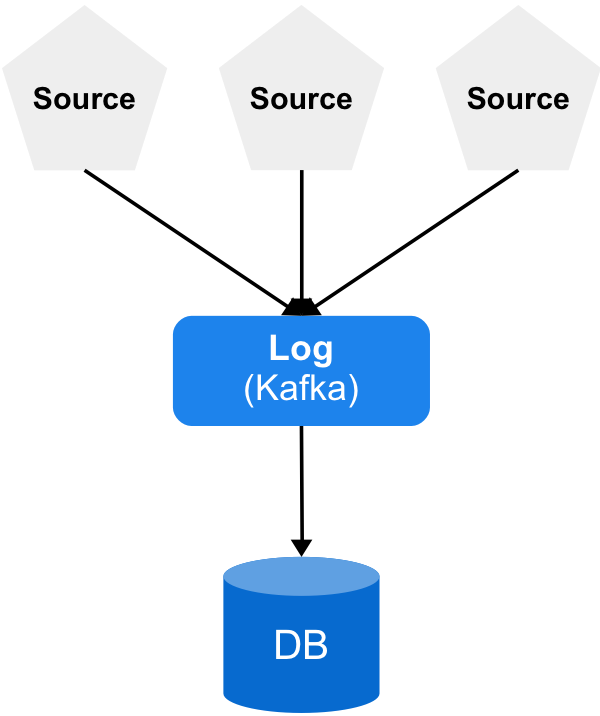
There are lots of sources that send their data to a log, which is usually a Kafka cluster. After the data are in Kafka, consumers (not displayed) read through the log and push to a database to be indexed and queried.
Kafka removes a lot of complexity from other components. As I mentioned in my previous post, if you do it the right way, you can even remove the durability requirement in your database. But eventually, Kafka starts to look like the big, monolithic component in the architecture.
Then I started thinking about how to get rid of it.
At the moment, I’m interested in aggregating system events (application log events, etc.) and web page views. The neat thing about these data is that they’re usually already logged at the source. My applications have logs, and web servers like Apache and nginx do too.
My logs are already at the edge, so I decided to keep them there and avoid using Kafka =).
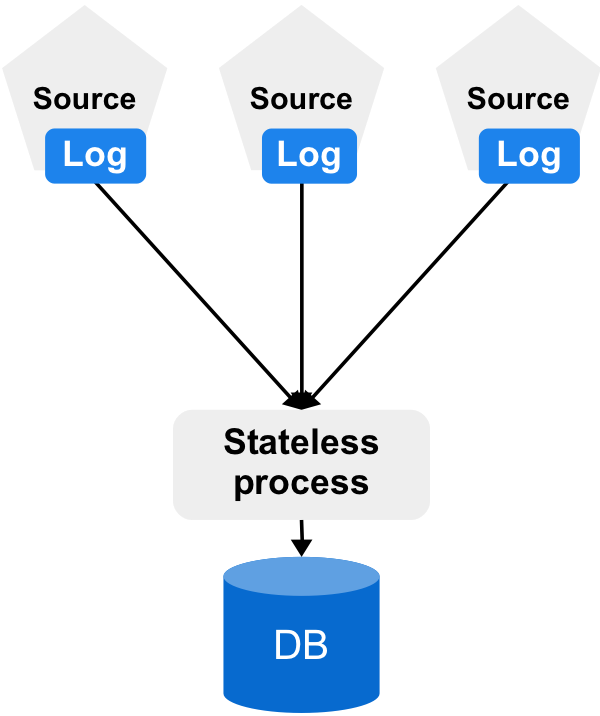
The downside is that this requires some more interaction between components in the architecture. But that’s not necessarily a bad thing. Instead of having a bunch of independent things just shoving data, I want to see if I can have a bunch of little things that are smart enough to work with the architecture. The nice thing about controlling the entire stack is that it’s probably way easier to do that.

Hi 👋. I’m a software engineer in the San Francisco Bay Area, and co-founder of FunnelStory.