Writing a database.
Early last month, I wrote Adversaria. I don’t have a precise definition for it, but I like to think of it as a tool to store time series data in key-value format. It’s really simple but useful. Using Adversaria and a little Flot magic, I make graphs like this:
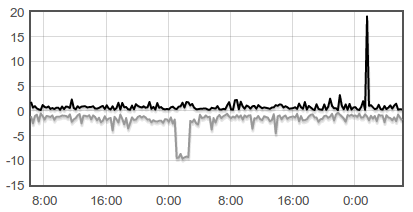
A few weeks ago, I decided to take it one step further. I felt that it was time to use whatever I learned to make that ad-hoc data storage solution to write a distributed key-value store.
Here’s what I envision: a simple, fast, clustered key-value store. It doesn’t sound too useful, does it? No map-reducing, no geospatial queries, no full-text searching, or anything complicated. I think it’s more realistic to build something simpler. The point is to not misframe, right?
Why?
I’ve always believed in learning by doing. Want to learn how a bridge works? Build a model. We did it in middle school using straws and that’s a great way of learning the basics of structural integrity. You can try out different methods and fundamentally understand why some things work and others don’t. It’s a more intuitive approach.
Elegance.
Elegance is great to think about. How do we keep things simple, yet effective? I feel that anyone could come up with a solution that works, but with a bit of clever thinking and some “secret sauce,” a more “elegant” solution can be developed.
A phrase that popped into my head is “first-class application logic.” I think it describes exactly what I’m trying to achieve. I’ll elaborate in a future post, but it’s essentially a combination of code elegance and run-time efficiency.
Any way, enough about the abstract.
How do we store data?
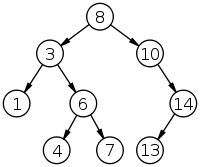
Adversaria uses TreeMaps internally to store key-values. TreeMaps are great because we can perform range operations like reading a range of values between two keys. For example, I read the values between 48 hours ago and now to make those cool graphs.
Trees can get slow. If we’re dealing with billions of keys, insertions and reads can take a while due to the inherent nature of the data structure. We’d like to minimize the number of operations we have to make. In that case, it sounds better to go with a hash-based map since we can get fast reads, but then we’ll lose the benefit of range operations.
Right now, I’m using a balanced binary search tree to store all of the keys in the keyspace. Of course, that means it’s sorted and that’s what we want. There’s also a hash map mapping the keys to their values. I don’t think it’s efficient to store the keys twice, but an obvious solution isn’t coming to mind. I’ll keep thinking about it.
Fault-tolerance?
This can get rather tricky to implement correctly, I think. I don’t really like the idea of master-slave replication. I think it’s easier to implement, but ideally that’s not what I would want.
Transactions?
Transactions are important. I recommend reading FoundationDB’s Transaction Manifesto for an in-depth look into transactions.
I have no idea how to implement transactions. What data structures should we use? How do we check transaction conflicts? I think finding the answers to these questions will take a bit of whiteboarding.
I like the phrase “patch-based transactional collision detection.” Not much more to say about that.
Transactions are closely tied together with ACID. I doubt that ACID compliance can be implemented any time soon…
Paranoia.
I think the most important thing about writing a distributed program is paranoia. As far as I know, nothing can be trusted. There are many moving parts in a distributed system and any one of them could fail. Failure should be expected. So, how do we prepare for failure? That’ll get answered as this project chugs along, I suppose.
One of the more interesting things about making something like this is that you really have to make it bulletproof. You have to simulate. You have to push the system to the extreme. You have to write test cases.
